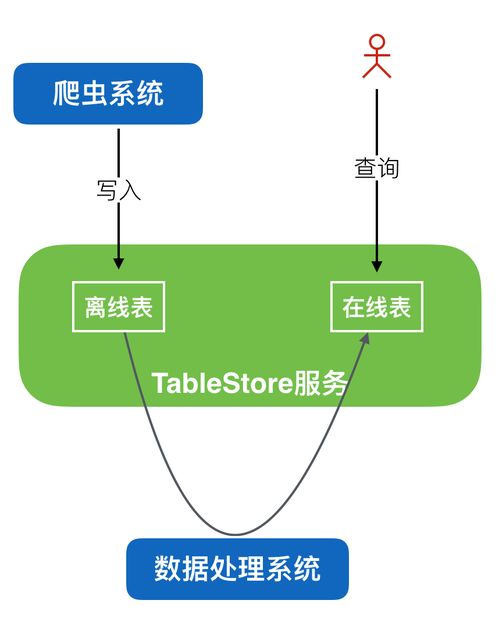
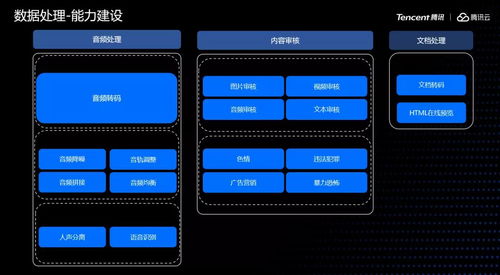
一、数据日志存储:Kafka的核心基石
Apache Kafka 作为一个高吞吐量的分布式消息系统,其核心设计之一便是高效、持久且可靠的数据日志存储。Kafka 的所有消息(记录)都以追加(Append-only)的方式顺序写入到磁盘的日志文件中,这种设计带来了优异的读写性能。
存储结构:
- 主题(Topic)与分区(Partition): 每个主题被划分为一个或多个分区,每个分区在物理上对应一个目录。
- 日志段(Log Segment): 每个分区又被进一步划分为多个日志段文件。活动段(active segment)负责接收新数据的写入,旧段文件在满足一定条件(如时间或大小)后变为不可变,并可能被清理或压缩。
- 索引文件: 为加速消息查找,Kafka 为每个日志段维护了位移索引(.index)和时间戳索引(.timeindex)文件,通过稀疏索引实现快速定位。
二、消息格式的演变与优化
Kafka 的消息格式(Record Format)历经了多次重要迭代,旨在提升效率、降低开销并支持更丰富的功能。
- V0/V1 格式(经典格式):
- 早期版本,消息批处理能力较弱,每条消息都包含完整的元数据(如CRC、魔术字、属性、时间戳等),网络和存储开销相对较大。
- V2 格式(自Kafka 0.11.0引入):
- 引入消息批次(Record Batch): 将多条消息聚合为一个批次进行存储和传输,批次头包含该批次公共的元数据(如首次位移、时间戳等),极大地减少了每条消息的元数据冗余。
- 更紧凑的变长字段: 使用变长整数(Varints)编码,进一步减少了空间占用。
- 支持幂等性和事务: 消息批次格式为 Kafka 实现精确一次语义(EOS)提供了基础。
格式的演进显著降低了网络传输和磁盘存储的开销,是 Kafka 实现高吞吐的关键之一。
三、日志压缩:保留关键状态
Kafka 提供了两种日志清理策略:基于时间的删除和基于日志压缩(Log Compaction)。
日志压缩是一种特殊的存储优化机制,它确保对于同一个 Key 的消息,Kafka 分区最终只保留其最新的 Value(即最后一条消息)。
- 工作原理: 后台的压缩线程会定期扫描日志,对于具有相同 Key 的消息,只保留位移最大的那条(最新值),删除旧的版本。没有 Key 的消息不会被压缩,通常会被基于时间的策略清理。
- 应用场景: 主要用于存储数据库变更日志(CDC)、应用状态快照等场景。例如,可以存储一个用户的最新配置、一个商品的最新价格。消费者可以从头读取压缩后的日志,获得所有 Key 的完整最新状态。
- 保证: 压缩操作不会改变消息的顺序,也不会影响消息的位移(Offset)。它提供的是“最终”的键值存储视图。
四、数据处理与存储服务:从管道到平台
凭借其强大的存储能力,Kafka 早已超越了简单的消息队列角色,演变为一个实时的流式数据处理与存储平台。
- 作为流式数据管道:
- Kafka 是连接不同数据系统(如数据库、应用、Hadoop、数据仓库)的可靠中枢,实现数据的实时流动。生产者和消费者模型解耦了数据生产方和消费方。
- 作为存储层:
- Kafka 持久化、可复制的日志设计使其本身成为一个高效的存储系统。数据可以按需保留很长时间(数天甚至数年),供多个消费者以各自的速度和时机进行读取(包括回溯历史数据),这是传统消息队列难以做到的。
- 与流处理集成:
- Kafka Streams: 一个用于构建实时流处理应用的客户端库,直接利用 Kafka 作为状态存储(State Store)。其底层正是利用了 Kafka 分区的日志存储和压缩机制来持久化应用的本地状态,实现了容错和可扩展的流处理。
- ksqlDB: 建立在 Kafka Streams 之上的流式 SQL 引擎,允许用户使用 SQL 语句对 Kafka 中的数据进行查询、转换和持久化,进一步简化了流处理应用的开发。
- 连接器生态(Kafka Connect):
- 提供了大量预构建的连接器,可以轻松地将外部系统的数据导入 Kafka(Source Connector)或将 Kafka 的数据导出到其他存储系统(Sink Connector)。这使得 Kafka 成为整个数据生态的枢纽,统一了数据存储和分发的接口。
##
Kafka 的数据日志存储是其所有高级特性的根基。从高效的日志段和索引设计,到不断优化的消息格式,再到提供关键状态保留能力的日志压缩,这些存储层的创新共同支撑了 Kafka 的高性能与可靠性。在此基础上,Kafka 通过 Streams API、Connect API 等,将自身从一个高性能的消息总线,升级为一个完整的实时流式数据处理与存储服务平台,使得数据的存储、流动和处理能够在同一个系统中无缝衔接,满足了现代数据密集型应用的苛刻需求。