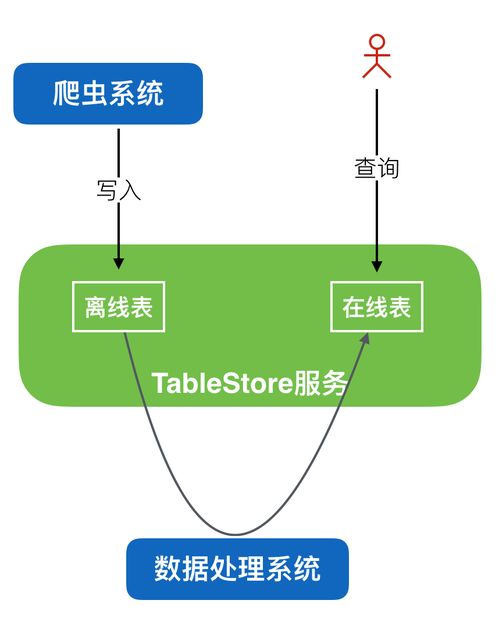
在当今数据驱动的时代,爬虫已成为获取海量信息的重要手段。随着数据量的激增,传统的关系型数据库在存储和查询爬虫数据时常常面临性能瓶颈和扩展性挑战。阿里云的Tablestore(表格存储)作为一种高性能、高扩展、全托管的NoSQL数据库服务,正成为处理大规模爬虫数据的理想选择,堪称数据处理与存储领域的利器。
一、Tablestore的核心优势:为爬虫数据量身打造
1. 海量存储与弹性扩展
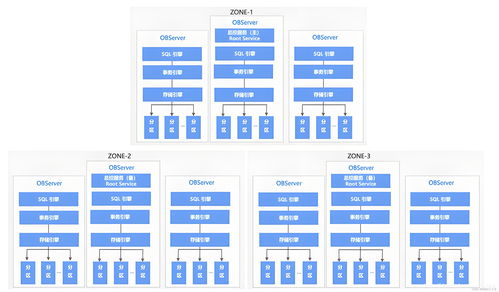
爬虫数据通常具有数据量巨大、增长迅速的特点。Tablestore支持PB级数据存储和万亿行级别数据规模,并能实现自动的弹性伸缩。用户无需预先规划容量,也无需手动分库分表,系统可根据数据量和访问压力自动调整资源,轻松应对数据量的爆发式增长。
2. 高性能读写与低延迟
对于需要实时入库和查询的爬虫应用,读写性能至关重要。Tablestore提供了极高的读写吞吐能力(单表可达千万级QPS)和毫秒级的低延迟访问。其数据模型(宽表模型)特别适合存储结构相对固定但可能包含大量列的爬虫结果(如网页标题、内容、URL、抓取时间、各类元数据等),支持高效的随机读写和范围查询。
3. 灵活的数据模型与多维度查询
Tablestore提供了两种数据模型:宽表(Wide Column)模型和时序(Timeline)模型。
- 宽表模型:非常适合存储结构化的爬虫数据。每行数据由主键(必须)和属性列(可选,可动态扩展)组成。例如,可以以
URL的MD5作为主键,存储该页面的所有抓取信息。
* 时序模型:特别适合存储按时间序列产生的爬虫状态、监控日志或增量内容更新。
Tablestore支持多元索引功能。即使查询条件不包含主键列,也能通过创建索引实现多条件组合查询、全文检索、模糊匹配、地理空间查询等复杂搜索,极大提升了数据查询的灵活性。例如,可以快速查询“某个域名下、最近一周抓取的、包含特定关键词的所有页面”。
4. 强大的数据生命周期管理
爬虫数据往往具有时效性,历史数据可能需要归档或清理以节省成本。Tablestore支持为表或数据行设置生存时间(TTL)。超过指定时间的数据会自动过期删除,这为管理海量历史爬虫数据提供了自动化、低成本解决方案。
二、典型应用场景与实践
1. 大规模分布式爬虫数据仓库
作为爬虫系统的核心存储,统一存储来自成千上万个爬虫节点的数据。利用其高吞吐能力,可以承受高并发写入;利用多元索引,可以方便地供下游分析系统或搜索服务进行多维度数据查询和消费。
2. 去重与增量抓取
利用Tablestore主键的唯一性,可以高效实现URL去重。爬虫程序在抓取前,先查询主键(如URL指纹)是否存在,从而避免重复抓取,节省资源。
3. 爬虫任务管理与状态跟踪
可以创建专门的表来管理爬虫任务队列、记录任务状态(待抓取、抓取中、成功、失败)、重试次数等信息。利用其高并发读写能力,多个爬虫节点可以高效、协同地领取和处理任务,避免冲突。
4. 内容分析与元数据存储
存储清洗和解析后的结构化数据,如商品信息、新闻文章、公司信息等。结合多元索引的全文检索和统计聚合能力,可以快速构建内部的数据查询平台或分析应用。
三、使用流程简述
- 规划数据模型:设计主键(通常选择能唯一标识数据的字段,如URL哈希),确定基本属性和需要建立多元索引的字段。
- 创建实例和表:在阿里云控制台或通过SDK创建Tablestore实例和数据表,根据需要配置读写容量、TTL等。
- 数据写入:爬虫程序通过官方提供的多语言SDK(Java, Python, Go, PHP等)将抓取到的数据以行为单位写入Tablestore。
- 建立索引:为需要复杂查询的字段创建多元索引。
- 数据查询与分析:通过主键查询、范围查询或多元索引查询来获取数据,供后续处理、展示或分析使用。
四、
Tablestore凭借其全托管、无限扩展、高性能、低成本的特性,完美契合了大数据爬虫场景下对数据存储与查询的苛刻要求。它将开发者从繁琐的数据库运维、分片设计和性能调优中解放出来,使其能够更专注于爬虫逻辑与数据价值挖掘本身。无论是构建大型垂直爬虫系统、通用搜索引擎的数据后端,还是进行海量网络数据的归档与分析,Tablestore都是一件值得信赖的“利器”,能够为数据处理与存储服务提供坚实、高效的底层支撑。