HBase是一个基于Hadoop的分布式、面向列的开源数据库,它能够处理海量数据,并提供高可靠性、高性能的数据存储与访问服务。本文将深入解析HBase的数据存储方式及其请求处理机制,以阐明其作为数据处理与存储服务的核心原理。
一、HBase的数据存储方式
HBase的数据存储采用了一种层次化的结构,主要包含以下几个关键组成部分:
- 表(Table):HBase中的数据存储在表中,表由行和列组成。与关系型数据库不同,HBase的表是稀疏的,允许动态添加列。
- 行(Row):每一行数据由一个行键(Row Key)唯一标识。行键是字节数组,在表中按字典顺序排序,这影响了数据的存储和检索效率。
- 列族(Column Family):列族是列的集合,在创建表时预定义。每个列族内的列可以动态添加,且同一列族的数据物理上存储在一起,这优化了存储和访问性能。例如,一个用户表可能包含“基本信息”和“联系信息”两个列族。
- 列限定符(Column Qualifier):列族下的具体列,通过列族与列限定符的组合(如“基本信息:姓名”)来唯一标识一个列。
- 时间戳(Timestamp):每个单元格(Cell)可以存储多个版本的数据,时间戳用于区分不同版本,默认按时间倒序排列,便于获取最新数据。
- 单元格(Cell):由行键、列族、列限定符和时间戳唯一确定的数据单元,存储实际的值(Value)。
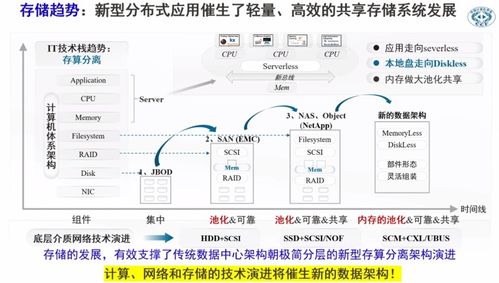
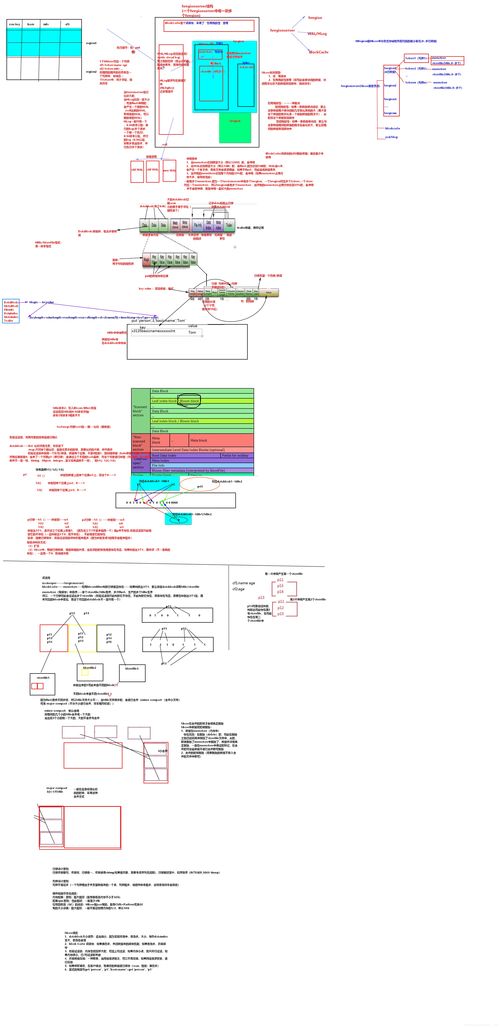
HBase的物理存储依赖于HDFS(Hadoop Distributed File System),数据以HFile格式存储在HDFS上。表被水平划分为多个区域(Region),每个Region负责表中一段连续的行键范围。随着数据增长,Region会自动分裂,以实现负载均衡。HBase使用MemStore(内存存储)缓存新写入的数据,定期刷写(Flush)到磁盘形成HFile,并通过压缩(Compaction)合并小文件,优化读取性能。
二、HBase的请求处理方式
HBase的请求处理涉及客户端、主节点(Master)和区域服务器(RegionServer)的协同工作,主要流程如下:
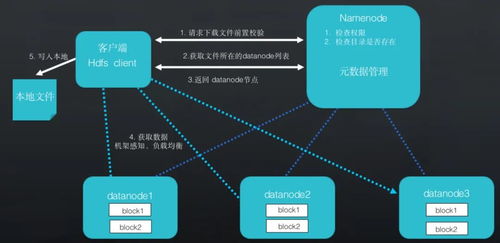
- 客户端请求发起:客户端通过HBase客户端API(如Java API)发起读写请求。对于写操作,客户端先将数据写入预写日志(WAL)确保持久性,然后存入MemStore;对于读操作,客户端根据行键定位目标Region。
- 元数据定位:客户端首先访问ZooKeeper(分布式协调服务)获取元数据表(hbase:meta)的位置。元数据表存储了所有Region的分布信息,包括RegionServer的地址和行键范围。客户端缓存这些信息,以直接与RegionServer通信,减少元数据查询开销。
- RegionServer处理:RegionServer是HBase的工作节点,负责处理具体的数据请求。每个RegionServer托管多个Region,并处理以下核心任务:
- 写请求:数据先写入WAL,然后存入MemStore。当MemStore满时,数据刷写到磁盘形成新的HFile。这种设计保证了高吞吐量的写入性能。
- 读请求:读取操作会同时查询MemStore和磁盘上的HFile,通过布隆过滤器(Bloom Filter)快速排除不包含目标数据的HFile,提高检索效率。HBase还支持缓存机制(BlockCache),将频繁访问的数据块缓存在内存中,加速读取。
- Region管理:RegionServer监控Region的大小,在超过阈值时触发分裂,并定期执行压缩以清理过期数据和合并小文件。
- 主节点协调:主节点负责集群管理,如Region分配、负载均衡和故障恢复。当RegionServer失效时,主节点会将其上的Region重新分配到其他健康节点,确保服务高可用性。主节点本身通常有备份节点,通过ZooKeeper实现故障转移。
- 数据一致性保障:HBase提供强一致性模型。所有读写操作都针对单个行键原子执行,客户端总能读取到最新写入的数据。通过WAL和分布式锁机制,HBase在节点故障时也能保证数据不丢失。
三、HBase作为数据处理与存储服务的优势
HBase的设计使其在大数据场景下表现出色:
- 高可扩展性:通过Region分裂和分布式存储,支持PB级数据水平扩展。
- 高性能读写:基于LSM树(Log-Structured Merge Tree)的存储引擎优化了写入吞吐,而缓存和索引机制提升了读取速度。
- 灵活的数据模型:面向列的存储支持稀疏数据,适合半结构化和非结构化数据。
- 强一致性与容错:依托HDFS和ZooKeeper,保障数据可靠性和服务连续性。
HBase通过其独特的数据存储结构和高效的请求处理机制,为大数据应用提供了强大的数据处理与存储服务。在实际应用中,如实时分析、日志处理和推荐系统等场景,HBase能够有效管理海量数据,满足高并发访问需求。理解这些原理有助于开发者更好地设计和优化基于HBase的解决方案。