JBD2与Hadoop:高效数据处理与存储服务的融合
引言
在大数据时代,数据处理与存储的效率直接决定了企业数据应用的能力。Linux内核中的JBD2(Journaling Block Device 2)与分布式计算框架Hadoop的结合,为海量数据的可靠存储与高效处理提供了坚实的技术基础。本文将探讨JBD2如何为Hadoop的数据存储提供底层支持,以及两者结合带来的优势与挑战。
一、JBD2:可靠的存储基石
JBD2是Linux内核中为文件系统提供日志(Journaling)功能的核心模块,主要用于ext4文件系统。其核心价值在于:
- 数据一致性保障:通过写前日志(Write-Ahead Logging)机制,确保即使在系统崩溃或意外断电时,文件系统也能快速恢复至一致状态,避免数据损坏。
- 高性能写入:将随机写入转化为顺序写入,显著提升磁盘I/O效率,尤其适用于Hadoop中频繁的数据写入场景。
- 元数据保护:优先保护文件系统元数据,这是保证Hadoop分布式文件系统(如HDFS)目录结构完整性的关键。
在Hadoop集群中,每个数据节点(DataNode)通常使用ext4文件系统来存储HDFS数据块,JBD2的日志功能为这些数据块的元数据操作提供了原子性和持久性保证,是HDFS高可靠性的重要底层支撑。
二、Hadoop:分布式处理与存储的引擎
Hadoop是一个开源的分布式系统基础架构,其核心组件包括:
- HDFS(Hadoop Distributed File System):高容错性的分布式文件系统,设计用于在廉价硬件上存储超大规模数据集。
- MapReduce:分布式计算框架,用于并行处理海量数据。
- YARN:资源管理与作业调度框架。
HDFS将大文件分割成多个数据块(默认为128MB或256MB),并跨集群中的多个数据节点进行复制存储(默认为3副本),从而实现数据的可靠存储与高吞吐量访问。
三、JBD2与Hadoop的协同工作
在实际部署中,JBD2与Hadoop的协同主要体现在存储层面:
- 数据写入流程:
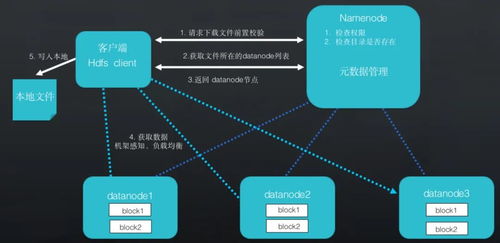
- 当HDFS客户端写入数据时,数据首先被分成块,并并行写入多个数据节点。
- 数据节点的本地文件系统(如ext4)接收到写入请求后,JBD2会先将本次写入的元数据变更记录到日志中,再实际修改文件系统。
- 这种机制确保了即使写入过程中系统崩溃,恢复后也能根据日志重放或撤销未完成的操作,保证HDFS数据块元数据(如inode、块映射)的一致性。
- 故障恢复加速:
- Hadoop集群规模庞大,节点故障是常态。当某个数据节点重启时,ext4文件系统借助JBD2可以快速恢复一致性状态,无需漫长的fsck检查,从而缩短节点恢复时间,提升集群整体可用性。
- 性能调优考量:
- 日志模式选择:ext4提供了
journal(全数据日志)、ordered(仅元数据日志,默认)和writeback三种日志模式。对于Hadoop,ordered模式在保证元数据一致性的性能开销较小,通常是推荐设置。
- 日志设备分离:在高性能集群中,可以将JBD2日志存放在单独的SSD或NVMe设备上,进一步减少日志写入对数据磁盘I/O的干扰,提升整体吞吐量。
四、优势与挑战
优势:
- 增强的可靠性:JBD2为Hadoop底层存储提供了企业级的数据一致性保障。
- 提升的写入性能:日志机制将随机写转为顺序写,契合磁盘物理特性,有利于HDFS的大量数据写入作业。
- 快速故障恢复:减少因节点重启导致的数据不可用时间,符合Hadoop设计的高容错目标。
挑战与注意事项:
- 性能开销:日志写入带来额外的I/O操作,在极端写入负载下可能成为瓶颈。需根据工作负载特点调整日志参数(如提交间隔)。
- 配置复杂性:优化JBD2与ext4参数(如
data=ordered,journal_dev)需要一定的系统管理经验。 - 替代方案:对于追求极致性能的场景,部分企业会考虑使用XFS或ZFS等其他文件系统,它们采用不同的日志或写时复制(Copy-on-Write)机制,与Hadoop的适配性也需评估。
五、最佳实践建议
- 文件系统配置:在Hadoop数据节点上格式化ext4时,建议使用
mkfs.ext4 -O ^has_journal先禁用日志,然后用tune2fs -j添加日志,以便正确对齐日志参数。挂载时使用defaults,noatime,nodiratime,data=ordered选项。 - 监控与调优:监控JBD2的日志写入量(可通过
iostat -x或/proc/fs/jbd2/查看)以及磁盘利用率,根据实际情况调整/proc/sys/fs/jbd2/下的内核参数(如commit_timeout)。 - 硬件优化:若条件允许,为日志分配独立的闪存设备,并确保数据磁盘使用RAID或JBOD配置符合Hadoop的冗余设计理念。
结论
JBD2作为Linux内核中成熟的日志块设备层,为Hadoop的分布式存储提供了不可或缺的底层数据一致性保障。虽然引入了一定的复杂度与性能考量,但其在可靠性与故障恢复方面的价值,使其成为生产环境Hadoop集群存储基石的常见选择。深入理解JBD2的工作原理,并结合Hadoop的数据访问模式进行针对性调优,能够有效构建出既稳健又高效的大数据处理与存储服务平台。随着存储硬件与文件系统技术的不断发展,这种协同也将持续演进,以应对日益增长的数据挑战。